Building a Real-Time Portfolio!
Hello and welcome to my Portfolio 4.0!
I had a lot of fun building this project and wanted to share a bit about the process.
I’ve always wanted to learn Kubernetes. I think it’s a really cool concept. Part of me still thinks it’d be awesome to become a certified Kubestronaut someday, but that’s a goal for another time.
Now, to be fair, I already had a perfectly good portfolio that worked fine and cost me nothing to run (other than my trustytea.me domain). So why rebuild it?
Pretty much no other reason than because I was bored 😄. I wanted to learn something new and needed a playground to test ideas out.
Planning the Build
I started by thinking about the architecture and what I wanted this project to do.
One of my early ideas was to have the portfolio’s front page automatically update based on my most recent GitHub work, and ideally in real time 🤯.
I also wanted to learn Angular, so I built the frontend with it.
For real-time communication between the frontend and the API, I used SignalR.
GitHub data retrieval runs as a background worker on my cluster every five minutes. GitHub’s rate limits are pretty high, so five minutes feels “real time” enough to me, where I didn't want to push it further.
I chose Kubernetes because I wanted a place where I could spin up workers easily and let them handle different jobs. Eventually, I’d like to move everything off the cloud and run it on my own servers at home to save costs — but for now, paying for cloud hosting is worth the learning experience.
And yes, I definitely went overboard for a personal portfolio, but that was kind of the point.
The Stack
At the moment, I have five services running on my cluster:
- Ghost (for my blog)
- GitHub Sync Worker
- Portfolio API
- Portfolio Frontend
- Redis
I use nginx as a reverse proxy and Ingress for routing.
My Ghost and API services are available at blog.ryanflores.dev and api.ryanflores.dev, respectively.
At one point, I tried integrating Ollama to generate AI summaries of my commits.
It was a cool idea, but in practice, AI is so unpredictable, inconsistent, and eats up too much memory. So I scrapped it. In the end, it freed up resources and simplified everything.
Architecture Overview
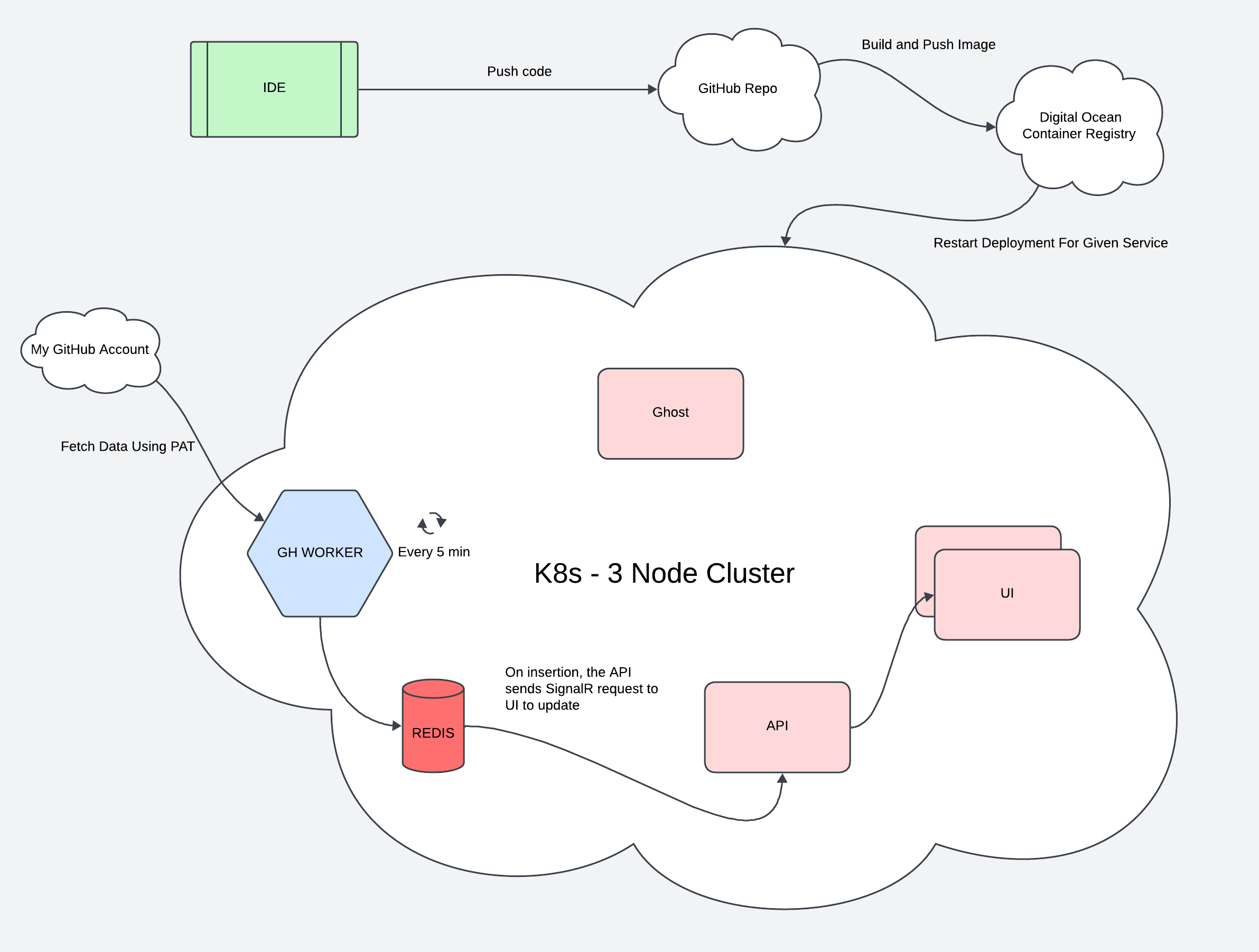
Here’s how it all fits together:
The frontend connects to the API using SignalR.
Whenever the Redis cache is invalidated, the API notifies all connected clients, which triggers an update on the UI.
I chose Redis over a relational database like PostgreSQL because I only care about my most recent commit data, not historical data. Redis is fast and keeps things simple.
Every five minutes, the background worker fetches data from GitHub using a personal access token. It stores the results in Redis and then notifies the API that new data is available. The API pushes those updates to the frontend instantly.
It’s a simple flow, and yes, I’ve definitely over-engineered it! But that’s exactly what made it fun 😊.
Reflections
This project doesn’t necessarily solve a “problem,” but it filled a gap in my learning. It reminded me that every decision comes with trade-offs, whether that’s performance, cost, or complexity.
In my case, the trade-off was spending a bit more money to gain a lot more knowledge (and a personal playground for future experiments).
One future idea: I think it'd be a fun project to build a worker that analyzes my World of Warcraft Mythic Dungeon runs with my family, tracking weekly damage totals, month-over-month progress, or seasonal stats. Just a little fun data-driven experiment like that.
Challenges and Lessons Learned
Not everything went smoothly, of course.
One of the first problems I ran into was with Ollama. I had originally planned to use it to generate commit summaries, but it just wasn’t stable. After a lot of trial and error, I realized the issue was probably memory constraints; I was only able to allocate less than a gig of memory to it. That definitely affected performance and made it unreliable. In the end, I cut Ollama entirely, and honestly, that made the system simpler and faster, and in my opinion, much more readable. Now you just read my most recent commits, which may be less fun, but they give you exactly what I wrote.
I also struggled with Ingress and nginx proxy configurations at first. I spent an entire night tinkering, reconfiguring, and restarting pods before I finally figured out what I’d done wrong. Once it clicked, everything worked perfectly, but that debugging session taught me more about Kubernetes networking than hours of tutorials ever could. Every time I got the urge to learn K8s, I would go on YouTube and watch the 1-2 hour-long videos and never came out of it feeling like I understood it, but I guess I'm much more of a hands-on learner.
Right now, I’ve got another issue I’m still thinking through. I’m running two replicas of the frontend, but only one of the backend. If I scale the backend, SignalR doesn’t know which API instance to connect to and maintain the connection, so the real-time updates break. I’ve read about using sticky sessions with Redis to solve this, which is perfect since I already use Redis elsewhere in the project.
Scaling multiple replicas for a personal site is definitely overkill, but that’s the whole point!